
Qu’est-ce que la notion d’apprentissage pour un ordinateur ?

L’apprentissage automatique est une technologie d’intelligence artificielle qui permet aux ordinateurs d’apprendre sans avoir été explicitement programmé à cet effet. Cependant, pour apprendre et évoluer, les ordinateurs ont besoin de données pour analyser et former. En fait, le Big Data est l’essence même de l’apprentissage automatique, et c’est la technologie qui permet de libérer tout le potentiel du Big Data. Découvrez pourquoi cette technologie et le Big Data dépendent l’un de l’autre.
Plan de l'article
- Qu’est-ce que l’apprentissage automatique ?
- Les différents types d’algorithmes d’apprentissage automatique
- À quoi sert l’apprentissage automatique ?
- Pourquoi utiliser l’apprentissage automatique avec le Big Data ?
- Comment cela fonctionne-t-il ?
- Pourquoi l’apprentissage automatique n’est rien sans Big Data ?
- Le Deep Learning, un sous-domaine de l’apprentissage automatique
- Réseaux de neurones
- L’analyse prédictive donne de l’importance au Big Data
- L’apprentissage automatique au service de la gestion des données
- Une mauvaise forme d’IA
Qu’est-ce que l’apprentissage automatique ?
Si l’apprentissage automatique ne date pas d’hier, sa définition exacte est encore confuse pour de nombreuses personnes. Concrètement , il s’agit d’une science moderne qui permet de découvrir des modèles et de faire des prédictions à partir de données. reconnaissance des formes et analyse prédictive. Les premiers algorithmes ont été développés à la fin des années 1950. Le plus célèbre d’entre eux n’est autre que le Perceptron.
A lire également : Machine à coudre enfant : les cinq meilleurs modèles pour jeunes créateurs

L’apprentissage automatique est très efficace dans les situations où des informations doivent être obtenues à partir d’ensembles de données volumineux, diversifiés et changeants, par exemple le Big Data . Lors de l’analyse de ces données, elle est beaucoup plus efficace que les méthodes traditionnelles en termes de précision et de rapidité. Par exemple, l’apprentissage automatique peut détecter une fraude potentielle en une milliseconde en fonction des informations associées à une transaction, telles que la quantité et l’emplacement, ainsi que des données historiques et sociales. Par conséquent, cette méthode est beaucoup plus efficace que les méthodes traditionnelles d’analyse des données transactionnelles, des données provenant des réseaux sociaux ou des plateformes CRM.
A lire aussi : Comment sera calculer les APL en 2021 ?
L’apprentissage automatique peut être défini comme une branche de l’intelligence artificielle qui inclut de nombreuses méthodes pour créez des modèles à partir de données. Ces méthodes sont en fait des algorithmes.
Un programme informatique traditionnel exécute une tâche en suivant des instructions spécifiques et donc de la même manière. Au contraire, un système d’apprentissage automatique ne suit pas les instructions, mais tire des leçons de l’expérience . Par conséquent, ses performances s’améliorent par rapport à l’ « entraînement » à mesure que l’algorithme est exposé à davantage de données.
Les différents types d’algorithmes d’apprentissage automatique
Il existe différents types d’algorithmes d’apprentissage automatique. En général, ils peuvent être divisés en deux catégories : surveillés et sans surveillance .
Dans le cas de l’apprentissage supervisé , les données utilisées pour la formation sont déjà « marquées ». Le modèle d’apprentissage automatique sait donc déjà ce qu’il faut rechercher dans ces données (modèle, élément…). À la fin de l’apprentissage, le modèle ainsi formé peut récupérer les mêmes articles sur des données non étiquetées.
Parmi les algorithmes surveillés, nous distinguons entre les algorithmes de classification (prédictions non numériques) et les algorithmes de régression (prédictions numériques). Selon le problème résolu, l’un de ces deux archétypes est utilisé.
L’apprentissage non supervisé, en revanche, entraîne le modèle sur des données sans étiquettes. La machine parcourt les données sans aucun indice et tente de découvrir des modèles ou des modèles qui y sont récurrents. Cette approche est souvent utilisée dans des domaines spécifiques tels que la cybersécurité.
Parmi les modèles sans surveillance, on distingue entre les algorithmes de regroupement (pour trouver des groupes d’objets similaires), les associations (pour trouver des connexions entre les objets) et la réduction des dimensions (pour sélectionner ou extraire des entités).
Une troisième approche est celle de l’apprentissage accru . Dans ce cas, l’algorithme apprend en essayant à plusieurs reprises d’atteindre un objectif spécifique. Il pourra essayer toutes sortes de techniques pour y parvenir. Le modèle est récompensé lorsqu’il s’approche de la cible, ou puni s’il échoue.
À quoi sert l’apprentissage automatique ?
Utilisation et applications
L’apprentissage automatique est à l’origine de nombreux services modernes très populaires. Les moteurs de recommandation utilisés par Netflix, YouTube, Amazon ou Spotify en sont des exemples.
Il en va de même pour les moteurs de recherche Web tels que Google ou Baidu. Les flux d’actualités des réseaux sociaux tels que Facebook et Twitter sont basés sur l’apprentissage automatique, tout comme les assistants vocaux tels que Siri et Alexa.
Toutes ces plateformes collectent des données sur les utilisateurs afin de mieux les comprendre et d’améliorer leurs performances. Les algorithmes doivent savoir ce que voit le spectateur, ce sur quoi l’utilisateur clique et à quelles publications il répond sur les réseaux. De cette façon, ils peuvent offrir de meilleures recommandations, réponses ou résultats de recherche.
Un autre exemple est celui des voitures autonomes . Le fonctionnement de ces véhicules révolutionnaires est basé sur l’apprentissage automatique. Toutefois, les performances de l’IA dans ce domaine sont actuellement limitées. Si vous parvenez à vous garer sur l’autoroute ou à suivre une voie, le contrôle total d’un véhicule dans une zone bâtie est une tâche plus complexe qui a entraîné plusieurs accidents tragiques.
Les systèmes d’apprentissage automatique excellent également dans le domaine des jeux . L’IA a déjà surpassé les joueurs dans le jeu Go, Chess, Queen ou Shogi. Il parvient également à triompher des meilleurs joueurs de jeux vidéo comme Starcraft ou Dota 2.
L’apprentissage automatique est également utilisé pour la traduction automatique de la langue et la conversion de langue à l’écran. Un autre cas d’utilisation est analyse des sentiments sur les réseaux sociaux, également basée sur le traitement du langage naturel (NLP).
L’apprentissage automatique est également utilisé pour analyser et classer automatiquement les radiographies médicales . L’IA s’avère très efficace dans ce domaine, parfois même plus que les experts humains dans la détection d’anomalies ou de maladies. Cependant, compte tenu des problèmes rencontrés, les spécialistes ne peuvent pas encore être complètement remplacés.
Plusieurs entreprises ont essayé d’utiliser l’apprentissage automatique pour examiner automatiquement les curriculum vitae des candidats . Toutefois, les préjugés dans les données de formation entraînent une discrimination systématique à l’égard des femmes ou des minorités.
En fait, les systèmes d’apprentissage automatique ont tendance à préférer les candidats dont le profil est similaire. comme pour les candidats actuels. Ils ont donc tendance à commettre et à intensifier la discrimination qui existe déjà dans le monde des affaires .
C’est un vrai problème, et Amazon, par exemple, a préféré cesser d’expérimenter dans ce domaine . De nombreuses entreprises tentent de remédier aux préjugés concernant les données de formation en IA, telles que Microsoft, IBM ou Google.
La technologie controversée de reconnaissance faciale est également basée sur l’apprentissage automatique. Ici aussi, les préjugés dans les données d’entraînement constituent un problème sérieux.
Ces systèmes sont principalement formés sur des photos d’hommes blancs, de sorte que leur fiabilité est beaucoup plus faible pour les femmes et les personnes de couleur. Cela peut entraîner des erreurs aux conséquences terribles.
Pourquoi utiliser l’apprentissage automatique avec le Big Data ?
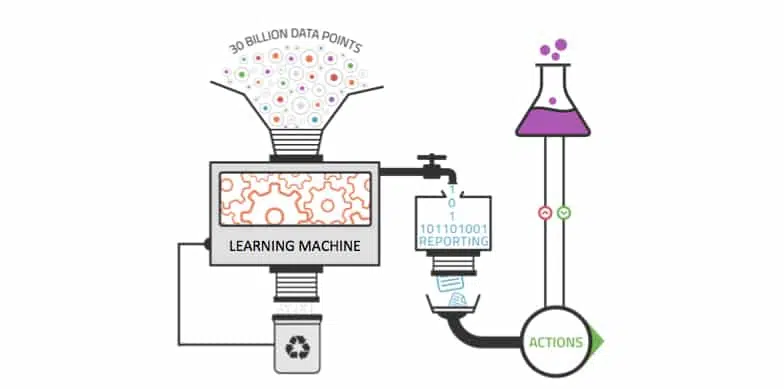
Les outils d’analyse traditionnels ne fonctionnent pas assez bien pour tirer pleinement parti de la valeur du Big Data. Le volume de données est trop important pour une analyse complète, et les corrélations et les relations entre ces données sont trop importantes pour que les analystes testent toute hypothèse permettant de tirer de la valeur de ces données.
Les méthodes d’analyse de base sont utilisées par les outils de Business Intelligence et de reporting pour générer des rapports sur les sommes, créer des comptes et exécuter des requêtes SQL . Les traitements d’analyse en ligne sont une extension systématisée de ces outils d’analyse de base qui nécessitent une intervention humaine pour spécifier ce qui doit être calculé.
Comment cela fonctionne-t-il ?
L’apprentissage automatique est idéal pour tirer parti des possibilités cachées du Big Data. Cette technologie permet d’extraire de la valeur à partir de sources de données massives et diverses sans avoir à faire appel à une personne . Il est piloté par les données et se prête à la complexité des énormes sources de données du Big Data. Contrairement aux outils d’analyse traditionnels, il peut également être appliqué à des ensembles de données croissants. Plus il y a de données introduites dans un système d’apprentissage automatique, plus ce système peut apprendre et appliquer les résultats à des informations de meilleure qualité. L’apprentissage automatique vous permet de découvrir des modèles enfouis dans les données avec plus d’efficacité que l’intelligence humaine.
Pourquoi l’apprentissage automatique n’est rien sans Big Data ?

L’apprentissage automatique et l’intelligence artificielle ne seraient rien sans le Big Data. Les données sont l’outil qui permet à l’IA de comprendre et d’apprendre les mentalités des gens . C’est le Big Data qui accélère la courbe d’apprentissage et vous permet d’automatiser l’analyse des données. Plus un système d’apprentissage automatique reçoit de données, plus il apprend et plus il devient précis.
L’intelligence artificielle peut désormais apprendre sans aide humaine. Dans le passé, le développement en raison du manque d’ensembles de données disponibles et de l’incapacité d’analyser d’énormes quantités de données, limite les données en quelques secondes.
Aujourd’hui, les données sont toujours accessibles en temps réel. Cela permet à l’IA et au machine learning de passer à une approche axée sur les données. La technologie est désormais suffisamment agile pour accéder à des ensembles de données colossaux et les analyser . En fait, des entreprises de différents secteurs se joignent désormais à Google et Amazon pour mettre en œuvre des solutions d’IA pour leurs entreprises.
L’un des principaux assureurs d’entreprise au monde, utilise cette technologie et le Big Data pour optimiser ses activités . La reconnaissance vocale lui a permis d’améliorer le suivi des accidents et de mieux mesurer leurs conséquences. Le traitement des réclamations est désormais mieux pris en charge, car les modèles de réclamations ont été enrichis de données non structurées utilisant cette technologie peuvent être analysés.
Le Deep Learning, un sous-domaine de l’apprentissage automatique
L’apprentissage automatique est un sous-domaine de l’intelligence artificielle. Le Deep Learning est en soi une sous-catégorie du machine learning. L’exemple le plus courant d’application est la reconnaissance visuelle. Par exemple, un algorithme est programmé pour reconnaître des visages spécifiques à partir d’images provenant d’une caméra. Localisez la quantité, trouvez le taux de satisfaction lorsque vous quittez un magasin en reconnaissant un sourire, etc. Un certain nombre d’algorithmes peuvent également reconnaître la voix, le son, l’expression d’une question, la confirmation et les mots.
Pour ce faire, l’apprentissage profond repose principalement sur la reproduction d’un réseau neuronal inspiré des systèmes cérébraux qui existent dans la nature. Les développeurs décident du type d’apprentissage qu’ils vont configurer en fonction de l’application qu’ils souhaitent. Dans ce contexte, nous parlons d’apprentissage supervisé, d’apprentissage non supervisé, où la machine se nourrit de données qui n’ont pas été précédemment sélectionnées, semi-surveillées, par amplification (liée à une observation), ou par transmission où les algorithmes appliquent une solution apprise dans une situation sans précédent est devenu.
En revanche, cette technique nécessite beaucoup de données pour s’entraîner et atteindre des taux de réussite suffisants pour être utilisée. Un lac de données ou un lac de données est essentiel pour perfectionner l’apprentissage des algorithmes d’apprentissage profond. Le Deep Learning nécessite également une plus grande puissance de calcul pour accomplir le travail. Vous devez vous équiper
Réseaux de neurones
Les réseaux de neurones artificiels s’inspirent de l’architecture du cortex visuel biologique. Le Deep Learning consiste en un ensemble de techniques qui permettent à un réseau de neurones d’apprendre à travers un grand nombre de couches pour identifier les entités.
De nombreuses couches sont masquées entre les entrées et les sorties du réseau . Chacun est composé de neurones artificiels. Les données sont traitées par chaque couche est = t les résultats sont transmis à la suivante.
Plus un réseau de neurones a d’épaisseurs, plus il faut de calculs pour l’exécuter sur un processeur. Les GPU, les TPU et les FPGA sont également utilisés comme accélérateurs matériels.
L’analyse prédictive donne de l’importance au Big Data

L’analyse prédictive consiste à utiliser des données, des algorithmes statistiques et des techniques d’apprentissage automatique pour prédire la probabilité de tendances commerciales et de résultats financiers en fonction du passé. Ils combinent diverses technologies et disciplines telles que l’analyse statistique, l’exploration de données, les modèles prédictifs et l’apprentissage automatique pour prédire l’avenir des entreprises. Par exemple, il est possible d’anticiper les conséquences d’une décision ou les réactions des consommateurs.
L’analyse prédictive peut fournir des informations exploitables à partir de grands ensembles de données afin que les entreprises puissent décider de la prochaine direction et offrir une meilleure expérience client. Avec plus de données, plus de puissance de calcul et le développement de logiciels d’IA et d’outils d’analyse plus conviviaux tels que Salesforce Einstein, de nombreuses entreprises peuvent désormais utiliser l’analyse prédictive.
L’intelligence artificielle et l’apprentissage automatique constituent le prochain niveau d’analyse des données. Les systèmes informatiques cognitifs apprennent constamment à connaître l’entreprise et prédisent intelligemment les tendances du secteur les besoins des consommateurs et bien plus encore . Peu d’organisations ont déjà atteint le niveau des applications cognitives définies par quatre caractéristiques clés : la compréhension des données non structurées, la capacité de raisonner et d’extraire des idées, la capacité d’affiner l’expertise à chaque interaction et la capacité de voir, de parler et d’entendre de la même manière que les gens qui interagissent. celui de cours. Pour ce faire, il est nécessaire de développer un traitement algorithmique des langages naturels.
L’apprentissage automatique au service de la gestion des données

Avec l’augmentation massive du volume de données stockées par les entreprises, les entreprises doivent faire face à de nouveaux défis. L’un des plus grands défis associés au Big Data est de comprendre les données sombres, conservation des données, intégration des données pour de meilleurs résultats d’analyse et accessibilité des données. L‘apprentissage automatique peut être très utile pour relever ces divers défis .
Au fil du temps, toutes les entreprises collectent de grandes quantités de données qui restent inutilisées . Il s’agit de données sombres. À l’aide de l’apprentissage automatique et de divers algorithmes, il est possible de trier ces différents types de données stockées sur des serveurs. Une personne qualifiée peut alors revoir le schéma de classification proposé par l’intelligence artificielle, apporter les modifications nécessaires et les mettre en œuvre.
Cette pratique peut également être efficace pour le stockage des données. L’intelligence artificielle peut identifier les données qui ne sont pas utilisées et suggérer celles qui peuvent être supprimées . Même si les algorithmes ne le font pas ont la même discrimination que les humains, l’apprentissage automatique permet de collecter un premier type de données. Cela permet aux employés de gagner un temps précieux avant qu’ils ne suppriment définitivement les données obsolètes.
Cette technologie est également utile pour l’intégration de données. Pour déterminer le type de données qu’ils doivent agréger pour leurs requêtes, les analystes créent généralement un référentiel dans lequel ils placent différents types de données provenant de différentes sources afin de créer un pool de données analytiques . Pour ce faire, des méthodes d’intégration doivent être développées pour accéder aux différentes sources de données à partir desquelles ils extraient les données. Cette technique peut simplifier le processus en créant des mappages entre les sources de données et le répertoire. Cela permet de réduire le temps d’intégration et d’agrégation.
Enfin, les données d’apprentissage permettent d’organiser le magasin de données pour un meilleur accès. Dans le au cours des cinq dernières années, les fournisseurs de stockage de données ont essayé d’automatiser la gestion du stockage . Avec la réduction du prix des SSD, ces avancées technologiques permettent aux entreprises informatiques d’utiliser des moteurs de stockage intelligents basés sur l’apprentissage automatique pour déterminer quels types de données sont les plus couramment utilisés et lesquels ne l’ont presque jamais été. L’automatisation peut être utilisée pour stocker des données basées sur des algorithmes. Par conséquent, l’optimisation n’a pas besoin d’être effectuée manuellement.
Une mauvaise forme d’IA
Dans les entreprises, certaines voix se font entendre pour rappeler que l’humanité est au début du développement de l’intelligence artificielle.L’apprentissage automatique est désormais une forme simple d’IA. Capable d’effectuer des tâches plus complexes que celles confiées à Skynet, le réseau informatique fictif du film Terminator. Qu’il s’agisse d’images, de sons, de textes ou d’algorithmes, des tâches simples sont exécutées. Ce n’est qu’en connectant des algorithmes que nous pouvons créer des systèmes plus intelligents. C’est ainsi que l’on pense aux voitures autonomes. Malheureusement, les acteurs de l’IA développent leurs solutions « dans leur coin ».








